
🙋♂️ Orest Kupyn
🙋♂️ Christian Rupprecht
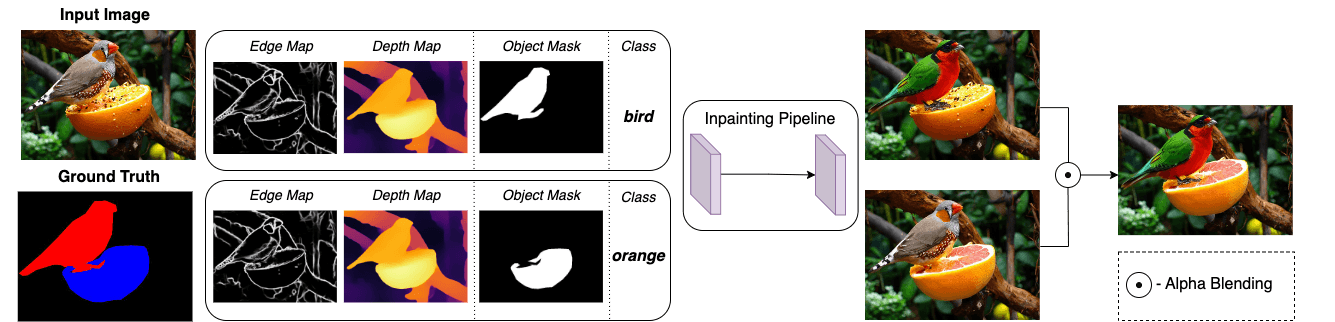
We propose a novel method for dataset enhancement with instance-level augmentations. Given an image and ground truth (or predicted) segmentation mask, we estimate depth and edge maps at the image level. The annotation is decomposed into the per-object binary masks and class, which together form the conditioning of the inpainting model. We redraw every instance and recombine them into a final image using alpha-blending sorted by depth. Used as a data augmentation method, it improves the performance and generalization of the state-of-the-art salient object detection, semantic segmentation and object detection models. By redrawing all privacy-sensitive instances (people, license plates, etc.), the method is also applicable for data anonymization.
We augment images by redrawing individual objects in the scene retaining their original shape. This allows training with the unchanged class label (e.g. class, segmentation, detection, etc.). The generations are highly diverse and match the scene composition. Guess the original in each row!






The method can generate images for an arbitrary dataset labelled with bounding boxes or segmentation masks, making it applicable for a wide range of tasks, including Object Detection, Semantic and Instance Segmentation, Panoptic Segmentation, etc.
We create an augmented version of DUTS - largest dataset for salient object detection. To construct the text prompt for the pipeline, we crop the image by the bounding rectangle of the binarized saliency map and use the BLIP-VQA model to predict the object name in an open vocabulary setting. The dataset is of relatively low resolution, which we also improve with our method. Since salient object segmentation highly depends on predicting accurate object boundaries, we add an optional mask refinement stage to preserve the sharpness and high quality of the masks. To this end, we crop every generated object from the images in the train set using its corresponding bounding rectangle of the saliency map. Below you can see an example of an original image and three augmented variants.












We evaluate the method on the COCO dataset, which is the largest dataset for object detection. The dataset includes complex scenes, with multiple objects, occlusions and various backgrounds. Still, the method generalize well to the complex scenes




The method can also be applied to the dataset that don't have the instance masks labels. In such case, the mask can be simply predicted by off-the-shelf model in open vocabulary setting. This allows to generate the augmentations for any object classes. To validate this, we regenerate Pascal VOC dataset for semantic segmentation without using the instance masks.


We validate that fully replacing people in the training data with synthetic samples does not affect the final performance, which enables retrospectively improving privacy shortcomings of scraped internet datasets. For the COCO dataset, we generate two additional versions: anonymizing people and cars (for personal information such as license plates). The visual examples of repainting people and vehicles are shown below.



import os
import cv2
import glob
from instance_augmentation.augment import Augmenter augmenter = Augmenter("path_to_save_results", p=1.0)
for image_path in glob.glob("path_to_image_folder/*"):
image_name = os.path.split(image_path)[1]
original_image = cv2.cvtColor(cv2.imread(image_path), cv2.COLOR_BGR2RGB)
augmented_image = augmenter.augment_image(original_image, image_name)
import cv2
import glob
from instance_augmentation.augment import Augmenter augmenter = Augmenter("path_to_save_results", p=1.0)
for image_path in glob.glob("path_to_image_folder/*"):
image_name = os.path.split(image_path)[1]
original_image = cv2.cvtColor(cv2.imread(image_path), cv2.COLOR_BGR2RGB)
augmented_image = augmenter.augment_image(original_image, image_name)
@article{kupyn2024dataset,
title = {Dataset Enhancement with Instance-Level Augmentations},
author = {Kupyn, Orest and Rupprecht, Christian},
journal = {arXiv preprint arXiv:2406.08249},
year = {2024}
}
title = {Dataset Enhancement with Instance-Level Augmentations},
author = {Kupyn, Orest and Rupprecht, Christian},
journal = {arXiv preprint arXiv:2406.08249},
year = {2024}
}
We would like to thank Tetiana Martyniuk for paper proofreading and valuable feedback.



© Piñata Farms AI 2024